Gustavo du Mortier is a functional and data analyst at MasterSoft, an Argentinean software company specializing in ERP and healthcare solutions. He’s written many books and articles on different aspects of programming and databases. In his spare time, he plays guitar and helps his two sons build and enhance their gaming computers.
In this guide, you’ll find all the necessary steps to create the perfect database design for a learning management system.
A database design for a learning management system must be able to gather and relate information about courses, course categories, students, course enrollments, teachers, classes, attendance, exams, and scores. Once you have this information in a database, you can use it to query relevant data and obtain all kinds of analytics, such as attendance rates per course and per teacher, pass rates, and score averages.
Don’t know exactly what data modeling is about? No worries! Read up on data modeling basics in 10 minutes and you will be right on track.
Before you start drawing the model, you’ll need to be familiar with the requirements and the scope of the project.
A requirements list for your learning management system database model might look like the one detailed below. This list must have the approval of the project stakeholders, so you can work safely. You’re less likely to hear that phrase that causes us software developers terror: “This is not what I asked for”. Remember that, among the many things that a database designer does, an important one is to correctly interpret what users and stakeholders really need.
The requirements list sets out the conditions, constraints, and criteria on which you will base your design. For a learning management system, these might include:
Requirements engineering also gives us a scope definition. That is the boundary that separates what the software will do from what it will not do.
It is convenient to state explicitly the functionalities that could be considered part of the system but that for some reason will be left out of the scope. For example:
Clearly establishing the limits of the scope of a project helps us avoid misunderstandings and false expectations about the development to be carried out.
The first step in designing your learning management system database model is to identify the entities for which you need to store information; these will end up becoming database tables. The input for this task should be a requirements list. By carefully reading this list, you will surely identify a set of entities like these:
You can now create a conceptual diagram for your learning management system that would contain all of these entities. But in order not to get into too much detail of the model creation process, let’s skip some steps and go directly to drawing the logical data model. This requires making a series of design decisions, supported by the requirements list.
You might want to learn more about the conceptual, logical, and physical data models before we continue. You can also check these example entity-relationship diagrams for ideas on other types of data models. You can use a tool like Vertabelo to do your data modeling tasks more efficiently.
After your logical data model is complete and validated, you will be able to create a physical model. But first, please read 8 things to consider when creating a physical data model to take advantage of the experience of someone that has done it quite a few times.
To identify the courses, students, teachers, and other entities of the schema, you may adopt the criterion of giving each element an alphanumeric identifier of 10 characters. These identifiers will be unique for each entity, so you can use them in each table as primary keys. Remember that you should always define a primary key for each table. If this is the first time you’ve seen the term “primary key”, maybe you should first read about what is a primary key before going any further.
The entities to be created can have other unique identifiers. In the case of students, for example, the email address should be unique for each student. This restriction can be enforced by assigning indexes that don’t allow duplicates. But it is not a good practice to use a field that could be modified (such as an email address) as a primary key. That’s why it’s advisable to use an abstract identifier as the primary key; this way, users can freely modify the rest of the data.
A good way to document your design decisions is to include text notes in your data models.
For each course, your database must be able to record the code, name, beginning/end date, an abstract of its contents, and the recommended bibliography. It should also indicate whether a course is open (signaling that it is open for enrollment) or closed (to prevent new students from enrolling). In addition, the course must be able to be associated with a certain category of courses.
Below, we’ll add all the information related to courses to our database schema: course schedules, the list of enrolled students, the list of teachers, attendance records, exams. but let’s take it one step at a time.
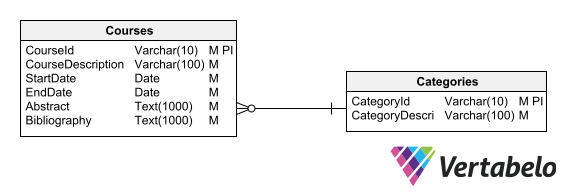
For now, you can diagram a basic outline for your Courses and Categories tables by drawing the two tables and setting a foreign key relationship between them.
A basic outline for the Courses and Categories tables.
An important question to decide when designing a learning management system data model is whether the same course can be taught again or only once in a lifetime.
Most commonly, the same course is taught repeatedly in successive years. But this poses a problem. When a course is repeated in a new academic year, how can you record the new start and end dates without losing the data from the previous academic year? The same will happen with the rest of the course information, since all the information may change from one academic year to the next.
One solution to the above problem is to normalize the schema. In the Courses table, you can leave only the data that does not necessarily change from one academic year to the next: code, description, course category, abstract, and bibliography.
Then you can create a table of academic cycles. (It’s better to use “cycles” instead of “years”, in case an academic cycle does not coincide with a calendar year). This table will contain the description of the academic cycles along with their start dates, end dates, holiday breaks, etc.
A third table will relate Courses to Cycles so we can identify the courses taught in each academic year. In this way, course data that varies from one year to another – such as start and end dates, faculty members, student enrollments, etc. – will be associated with this table instead of being associated with the “mother” Courses table.
With these modifications, your diagram would look like this:
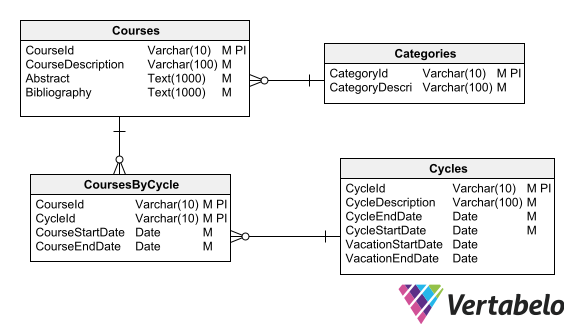
An improved version of the schema, after applying some normalization.
Up to this point, your schema is capable of storing course data and associating it with academic cycles. Now you should add the capability of registering the data of the students attending a given course.
To do this, you’ll first add a Students table. This table will have the following attributes: the student’s ID number (an alphanumeric code), name, email address, and optionally their birth date and phone number. The alphanumeric code will identify each student univocally, so you can use it as the primary key.
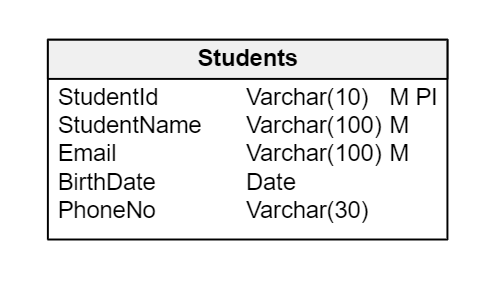
The Students table definition.
Then you need to think about how you’ll store enrollment data. You know (following the requirements definition) that each student can be enrolled in one, none, or many courses. And you know that each course can have any number of students enrolled. It is very clear, then, that there is a many-to-many relationship between Students and Courses .
Let us now consider which of the two courses tables ( Courses or CoursesPerCycle ) should be related to the Students table. When a student enrolls in a course, they do so for a given academic cycle. In other words, enrollment in a course is not a permanent thing; it is only valid for the duration of one cycle. For this reason, you should link the Students table to the CoursesPerCycle table instead of linking it to the main Courses table.
To link students with their courses, you’ll need the Enrollments table. This will contain the course ID, the cycle ID, and the student ID, which will form a composite primary key: no student can take the same course more than once per cycle. (If the student takes the course a second time, that will be in a different cycle.) You’ll also store the date of enrollment and a Boolean value indicating if the student canceled their enrollment in this course. The optional CancellationReason column will record the reason for the cancellation.
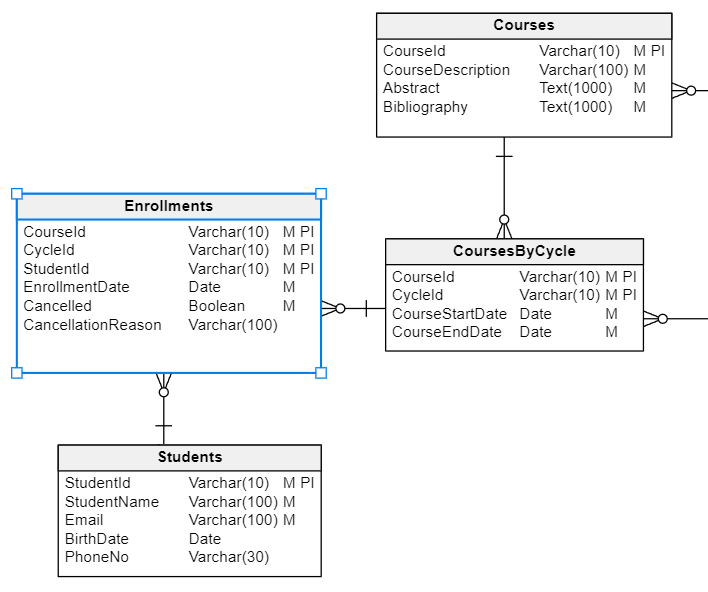
The Enrollments table links the Students table with the CoursesPerCycle table.
The Teachers table will be designed in a similar way to the Students table. It will have an alphanumeric ID that you can define as the primary key. In addition, it will have fields to store the teacher’s name and their email address, as well as an optional field for a phone number.
Each course can be taught by one or more teachers, and each teacher can teach one or more courses. Therefore, there must be a many-to-many relationship between courses and teachers, which will be materialized in a table called TeachersPerCourse . It will contain links to the CoursesPerCycle and Teachers tables.
This part of the schema should look something like the following:
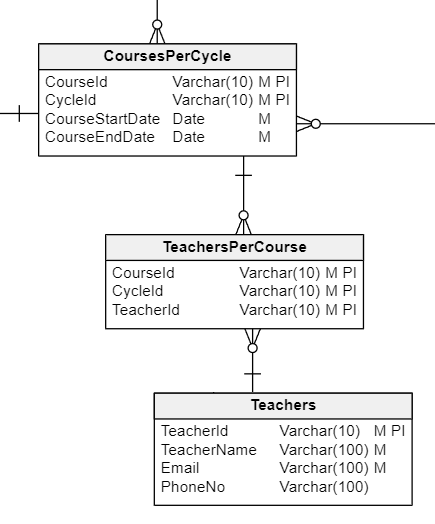
The TeachersPerCourse table links the Teachers table with the CoursesPerCycle table.
To fulfill the complete list of requirements, you only need to add entities for student attendance and test results.
To register students’ attendance in a course, you need a Classes table; a row is stored for each class taught in the course. A class belongs to a course and an academic cycle, so you’ll need a one-to-many relationship between Classes and CoursesPerCycle .
Each class must have a date, start time, end time, and a teacher. (To avoid overcomplicating the schema, you can assume that each class is taught by a single teacher.) In addition, you can give each class a sequential number and a title or description of the subject matter:
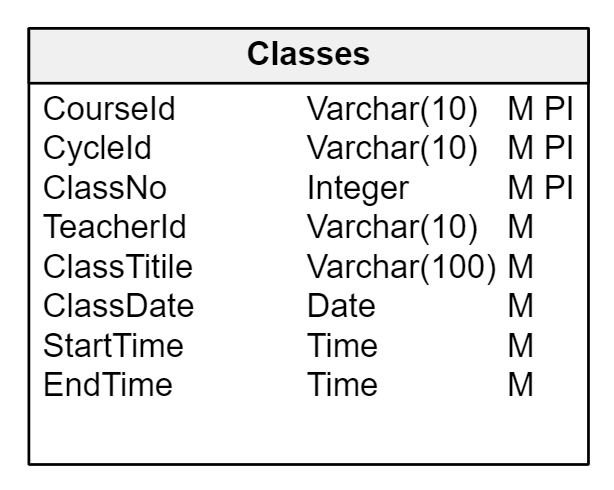
The Classes table is a subordinate of CoursesByCycle. Therefore, its primary key is composed of that of its master table with the addition of a correlative number (ClassNo).
Each class may be attended by many students, and each student may attend many classes. Therefore, you’ll need a many-to-many relationship between Students and Classes .
This relationship will have two attributes of its own: TimeArrive and TimeLeave . These register students’ time spent in the classes (although you may make this data optional, in case you don’t need so much detail about the students):
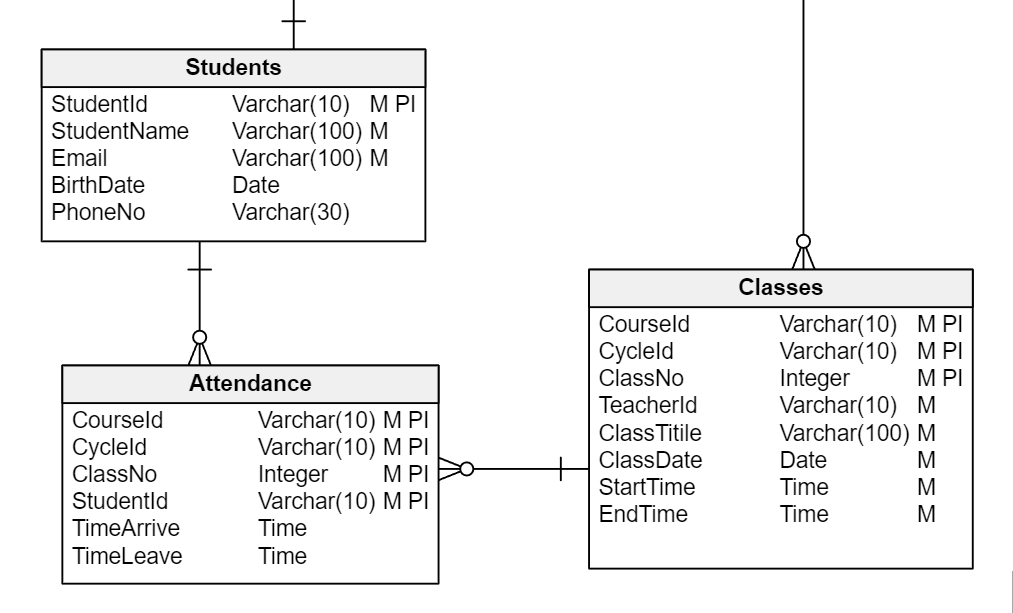
The Attendance table links Students with Classes, adding two attributes of its own: TimeArrive and TimeLeave.
The only thing left to do is create a Tests table and link it to the Courses table in a similar way as you did with Classes . Tests will also be associated with the CoursesPerCycle table. You can give each test a correlative number, a date, a time, and a free text field to contain the test topics.
Then you can create another table, TestScores , where the test results can be stored. This table links Tests with Students . This part of the schema should look like this:
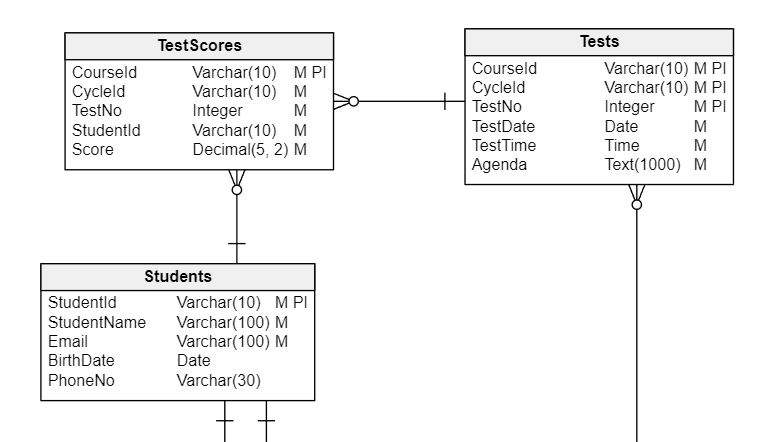
The tests and scores sub-schema.
With these last additions, you have covered all the requirements. Now you can present the complete database design:
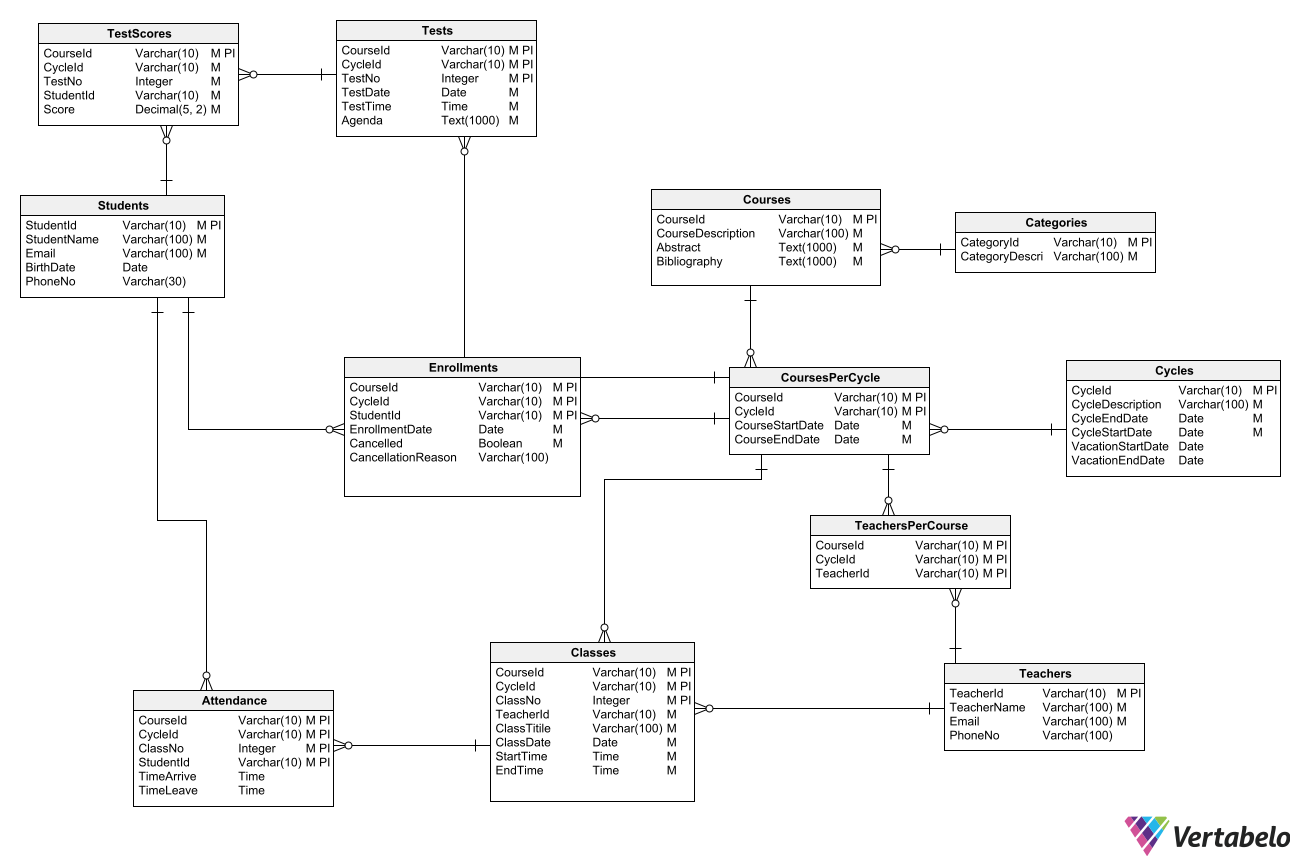
The complete database model for a learning management system.
This diagram allows you to generate a database that meets the requirements stated at the beginning of this article. By making some changes, it could be adapted to a different set of requirements. For example, for an online course management system, the dates and times of classes and exams would be irrelevant. Each student could freely choose when to take a class or an exam. It could also be that the concept of an academic cycle does not apply because courses are always current and are not tied to an academic year.
All these changes are relatively easy (and inexpensive) to make as long as they are made early in the software development life cycle. For this purpose, it is convenient to work as much as possible with the logical diagram, converting it into a physical diagram only when it is time to implement it on a given database engine. A design tool such as Vertabelo is an ideal ally to make the most of the resources related to data modeling and database design.
Subscribe to our newsletter Join our weekly newsletter to be notified about the latest posts. Subscribe